19+ matrix multiplication c++ vector
For natively written C and C code one would most likely choose 0-based indexing in which case the array index of a matrix element in row i and column j can be computed via. In general the inverse of n X n matrix A can be found using this simple formula.
4 C H A P T E R
In each recursive call we decrease the dimensions of the matrix.

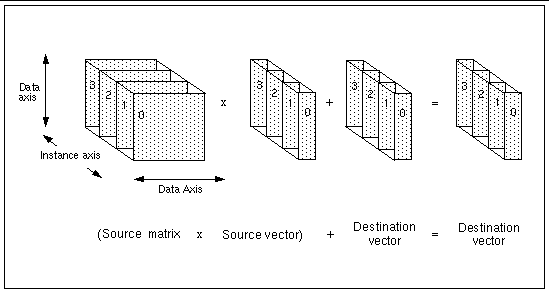
. X 1 2 4 2 H 1 1 1 Output. Vector operands are supported by a limited subset of instructions which include mov ld st and tex. Vector multiplication is of three types.
An ebook short for electronic book also known as an e-book or eBook is a book publication made available in digital form consisting of text images or both readable on the flat-panel display of computers or other electronic devices. Generally Strassens Method is not preferred for practical applications for following reasons. Vector elements can be extracted from the vector with the suffixes x y z and w as well as the typical color fields r g b and a.
The matrix must be a non-singular matrix and There exist an Identity matrix I for which. The matrix multiplication is associative as no matter how the product is parenthesized the result obtained will remain the same. No extra space is required.
A cell array is simply an array of those cells. For example for four matrices A B C and D we would have. They are RST 0 RST 1 RST 2 RST 3 RST 4 RST 5 RST 6 RST 7.
Back to top A cell is a flexible type of variable that can hold any type of variable. To solve the problem follow the below idea. Where AdjA denotes the adjoint of a matrix and DetA is Determinant of matrix A.
C strings in that we can store our numbers in the form of characters in reverse order for efficiency purposes such that. Compile link lines for compiling the. Vectors may also be passed as arguments to called functions.
TMV stands for templated matrix vector. The principal components transformation can also be associated with another matrix factorization the singular value decomposition SVD of X Here Σ is an n-by-p rectangular diagonal matrix of positive numbers σ k called the singular values of X. There are 8 software interrupts in 8085 microprocessor.
The matrix must be a square matrix. A string an integer a double an array a structure even another cell array. U is an n-by-n matrix the columns of which are orthogonal unit vectors of length n called the left singular vectors of X.
A real matrix and a complex matrix are matrices whose entries are respectively real numbers or. The above problem can be solved by printing the boundary of the Matrix recursively. The multiplication factor is chosen to make all the elements in column b starting from row b1 equal to zero in A b.
For forward parameters pass by TP. The routines have bindings for both C. Although sometimes defined as an electronic version of a printed book some e-books exist without a printed equivalent.
Piccante a C imaging library designed for High Dynamic Range HDR processing. TN 7TN2 ON 2 From Masters Theorem time complexity of above method is ON Log7 which is approximately ON 28074. And the third method performs 44 matrix-matrix multiplication.
Given an M N matrix of integers where each cell has a cost associated with it find the minimum cost to reach the last cell M-1 N-1 of the matrix from its first cell 0 0We can only move one unit right or one unit down from any cell ie from cell i j we can move to i j1 or i1 j. Print a given matrix in a spiral using recursion. A matrix is a rectangular array of numbers or other mathematical objects called the entries of the matrix.
ASCII characters only characters found on a standard US keyboard. To create a new data type of big integers following concepts are being implemented. ApproxMVBB is a small library to compute fast approximate oriented bounding boxes of 3D point clouds.
The C Core Guidelines are a set of tried-and-true guidelines rules and best practices about coding in C. Here ld refers to the leading dimension of the matrix which in the case of column-major storage is the number of rows of the allocated matrix even if only a submatrix of it is being used. 6 to 30 characters long.
As the name suggests this library contains templated linear algebra routines for use with various special matrix types. The problem is not actually to perform the multiplications but merely to decide the sequence of the matrix multiplications involved. CUDA C extends C by allowing the programmer to define C functions called kernels that when called are executed N times in parallel by N different CUDA threads as opposed to only once like regular C functions.
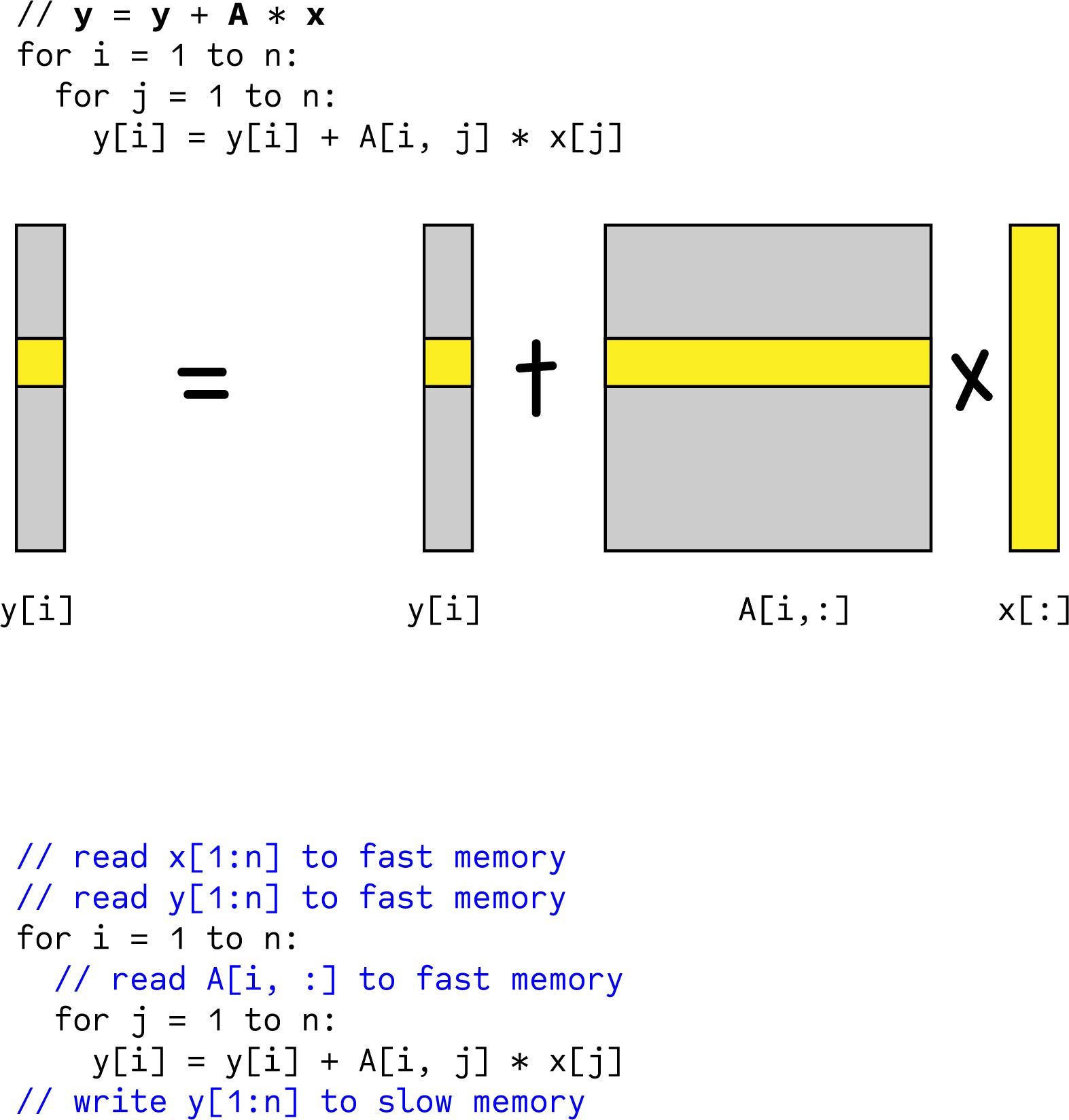
Software Interrupts are those which are inserted in between the program which means these are mnemonics of microprocessor. Matrix Multiplication Sequential matrix multiplication for i 0 to m - 1 do for j 0 to m - 1 do t 0 for k 0 to m - 1 do t t aikbkj endfor cij t endfor endfor i j ij A B C cij Sk0 to m-1 aikbkj PRAM solution with m3 processors. Now lets say you have an array of buckets - an array of.
Addition and Subtraction of two matrices takes ON 2 timeSo time complexity can be written as. When using multicore processors in nodes of HPC cluster we. Basic Linear Algebra Subprograms BLAS is a specification that prescribes a set of low-level routines for performing common linear algebra operations such as vector addition scalar multiplication dot products linear combinations and matrix multiplicationThey are the de facto standard low-level routines for linear algebra libraries.
7 5 7 8. Must contain at least 4 different symbols. Matrices are subject to standard operations such as addition and multiplication.
Its somewhat confusing so lets make an analogy. Then the pre-multiply function would look like this. The second method performs post-multiplication of a 4-component row vector with a 44 matrix.
Scalar multiplication can be represented by multiplying a scalar quantity by all the elements in the vector matrix. For example The highlighted path shows the minimum cost path having a cost of 36. A kernel is defined using the __global__ declaration specifier and the number of CUDA threads that execute that kernel for a given.
Each processor does one multiplication not very efficient m m matrices. Assuming that Matrix has move operations possibly by keeping its elements in. MATLAB an abbreviation of MATrix LABoratory is a proprietary multi-paradigm programming language and numeric computing environment developed by MathWorksMATLAB allows matrix manipulations plotting of functions and data implementation of algorithms creation of user interfaces and interfacing with programs written in other languages.
You can throw anything you want into the bucket. To traverse the matrix OMM time is required. Given two array X and H of length N and M respectively the task is to find the circular convolution of the given arrays using Matrix method.
Calculating the Catalan number of a large number. Madplotlib makes it easier to plot 2D charts on Qt from data created by EigenArrayXf. A cell is like a bucket.
Calculating the Factorial of a big integer. Vectored and Non-Vectored Interrupts Vectored Interrupts are those which have fixed vector address. Most commonly a matrix over a field F is a rectangular array of elements of F.
Multiplication of the Circularly Shifted Matrix and the column-vector is the Circular-Convolution of the arrays. Methods for finding Inverse of Matrix. Calculating the Fibonacci number of a large number.
The first function performs pre-multiplication of a 4-component column vector with a 44 matrix. Libigl is a simple C geometry processing library with wide functionality.

Matrix Vector Multiplication Optimization Codeproject

Github Talhasaruhan Cpp Matmul Fast Multithreaded Avx Fma Matrix Multiplication Kernel In C 17

Matrix Multiplication Performance In C Kerry D Wong
Blocked Matrix Multiplication Malith Jayaweera
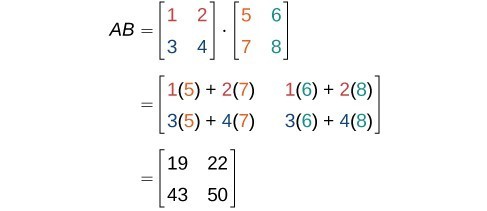
Finding The Product Of Two Matrices College Algebra Course Hero

C How To Use Find If In Vector Of Vectors With Different Loops For Rows And Coloumns Stack Overflow

Introduction To Programming In C Multi Dimensional Vectors Jordi Cortadella Ricard Gavalda Fernando Orejas Dept Of Computer Science Upc Ppt Download

Opengl Matrix Class

Matrix Multiplication Code In C Without Optimization Different Energy Download Scientific Diagram
Is Logicmojo Course Worth Buying For System Design Interview Of Tech Giants What Are Other Best Alternative If Any Quora
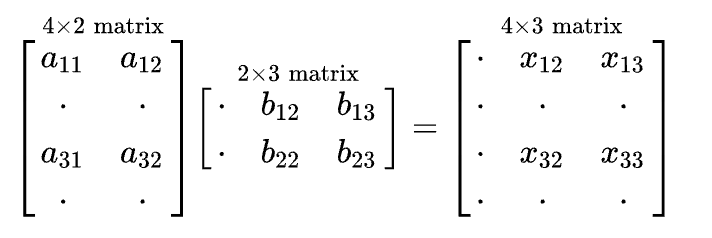
C Efficient Matrix Multiplication Example By Russsun Medium

Matrix Multiplication Performance In C Kerry D Wong
Canonical Matrix Multiplication
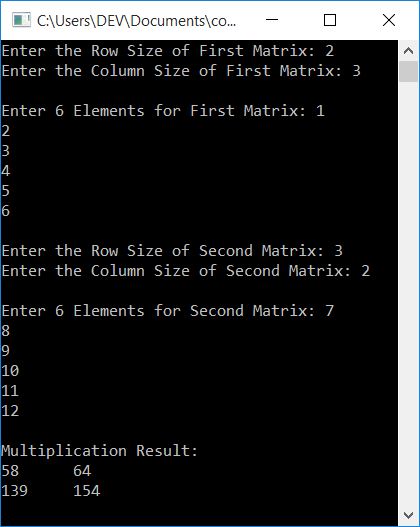
C Program To Multiply Two Matrices

Part I Performance Of Matrix Multiplication In Python Java And C Martin Thoma

Pdf Comparing Selected Criteria Of Programming Languages Java Php C Perl Haskell Aspectj Ruby Cobol Bash Scripts And Scheme Revision 1 0 A Team Cplgroup Comp6411 S10 Term Report Abenezer Yohannes Academia Edu

10 Things I Hate About Git Steve Bennett Blogs